
| 일 | 월 | 화 | 수 | 목 | 금 | 토 |
|---|---|---|---|---|---|---|
| 1 | 2 | 3 | 4 | 5 | 6 | 7 |
| 8 | 9 | 10 | 11 | 12 | 13 | 14 |
| 15 | 16 | 17 | 18 | 19 | 20 | 21 |
| 22 | 23 | 24 | 25 | 26 | 27 | 28 |
- timestamp
- 최대공약수
- 최소공배수
- C++
- coursera
- 자료구조
- 백준
- 알고리즘
- Andrew Ng
- AVLTree
- 과제
- CREATE TABLE
- BFS
- ML
- Machine Learning
- 데이터베이스
- pgadmin
- postgresql
- udemy
- COALESCE
- 유데미
- self join
- BST
- nullif
- 너비우선탐색
- 개발
- 시퀄
- Advanced SQL
- 깊이우선탐색
- sql
- Today
- Total
승1's B(log n)
[Coursera - Machine Learning] 머신러닝 스터디 Week 2 본문
22-1학기 기말고사가 모두 종료되어 드디어 시험기간 전에 했던 머신러닝 스터디의 Week 2를 업로드할 수 있게 되었다!
Week 2에서는 크게 Linear Regression with multiple variables와 Linear Algebra의 복습을 했다고 할 수 있다.
1. 다중선형회귀(Linear Regression with Multiple Variables)
(1) 다중선형회귀의 개념(Definition of Multivariate Linear Regression)
Week 1에서는 변수가 하나인 단일선형회귀를 배웠다면, Week 2에서는 변수가 여러 개인 다중선형회귀를 배웠다는 차이점이 있다.
현실에서는 하나의 변수만이 결과에 영향을 주는 경우보다 여러 개의 변수들이 결과에 영향을 주는 경우가 더 많다. 그렇기에 기계학습을 공부하기 위해서는 다중선형회귀를 필수적으로 공부해야 한다. 다중선형회귀에 대한 자세한 이야기를 풀기 전에, 다중선형회귀에서 쓰일 notation을 잠깐 정리해보려고 한다.

n은 feature의 수를 의미하고, $x^{(i)}$은 i 번째 training example의 열을 의미하게 된다.
예컨대, 다음 사진과 같은 상황에서 $x^{3}$은 training example의 세번째 열인 Number of floors를 의미하게 된다. 즉, [1, 2, 2, 1 ...]을 의미하게 되는 것이다.
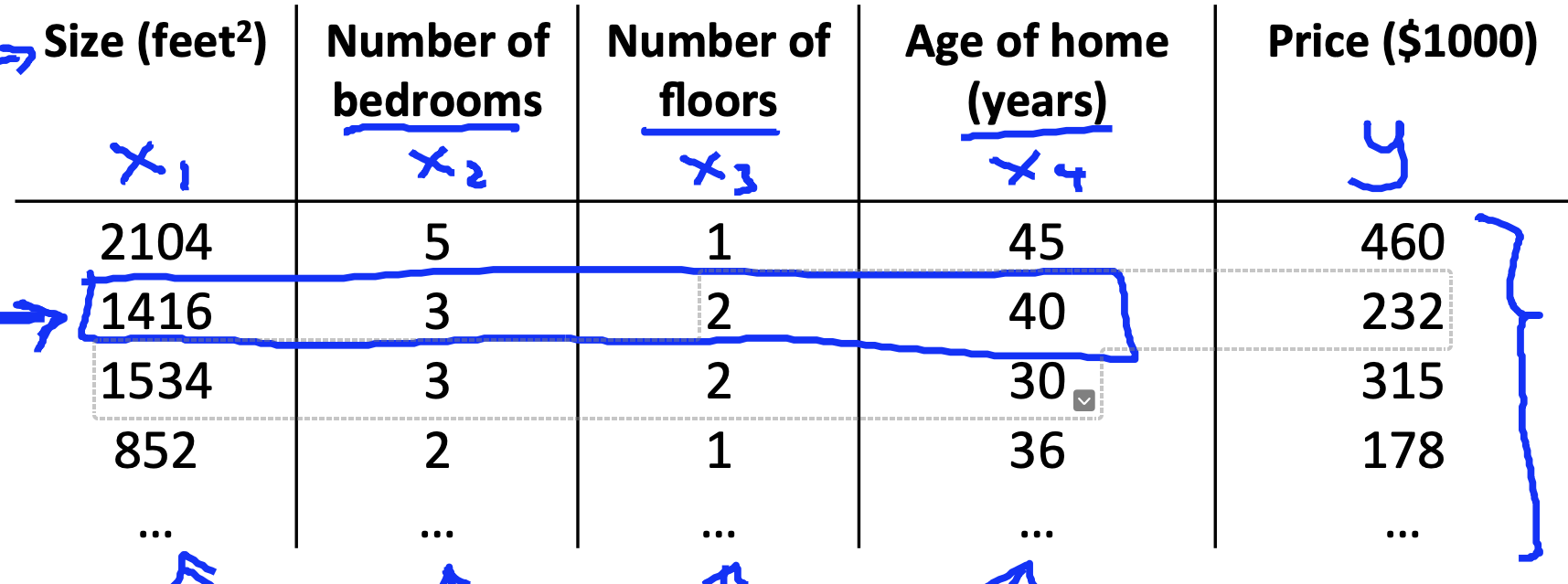
$x_{j}^{(i)}$에서 j는 행, i는 열을 나타나게 되는데, 특정한 training example 하나만을 지칭하기 위해서 사용된다. 예컨대, $x_{2}^{3}$은 Number of floors열의 두번째, 2를 의미하게 된다. (해당 포스트에서는 열과 행의 index를 1부터 시작하는 것으로 가정한다.)

단일선형회귀에서 하나의 변수만이 수식에 포함된 것에 반해, 다중선형회귀에서는 n개의 변수들이 수식에 포함된 것을 확인할 수 있다. $\theta _{0}$는 수식을 표현하기 쉽게 추가한 것으로 $x _{0} = 1$이 뒤에 곱해진 것으로 본다. 덕분에 이 수식의 형태는 선형결합의 형태로 표현 가능해진다. "$h_{ \theta } (x) = \theta ^{T}x$" 이런 식으로 말이다. 여기서 $x$는 $x = \begin{bmatrix} x_{0}\\ x_{1} \\ x_{2}\\ \vdots \\ x_{n} \end{bmatrix}$의 벡터이고, $\theta$는 $\theta = \begin{bmatrix} \theta _{0}\\ \theta _{1} \\ \theta _{2}\\ \vdots \\ \theta _{n} \end{bmatrix}$의 벡터이다. 따라서 $x$와 $\theta$는 각각 n+1 차원에 속하는 것이다. 그렇기에 $x$와 $\theta$의 선형결합으로 이루어진 $h_{ \theta } (x)$도 n+1 차원에 속하게 된다.
(2) 다중선형회귀에서의 손실함수와 경사하강법(Cost Function and Gradient Descent at Multivariate Linear Regression)

손실함수의 형태는 단일선형회귀에서의 모습과 크게 다르지 않다. 차이점이라면 손실함수 $J$의 파라미터로 여러 개의 세타 값이 들어간다는 것이다.
참고) 단일선형회귀에서의 손실함수 형태

경사하강법도 큰 틀에서는 다르지 않다.

다만 세부적인 부분에서는 차이가 있다. 파라미터가 복수이기 때문에 단일선형회귀에서는 두번의 스텝으로 해결이 가능했다면, n개의 변수를 가지는 다중선형회귀에서는 n번의 스텝을 거쳐야 한다.

(3) 경사하강법에서의 피쳐 스케일링(Feature Scaling at Gradient Descent)
결과에 영향을 주는 변수가 늘어날 수록 각각의 변수가 가지는 가중치의 값이 제각각이 되어버린다. 어떤 변수의 범위는 아주 작아서 결과에 미치는 영향이 미미한 반면에, 어떤 변수의 범위는 아주 넓어서 결과에 미치는 영향이 지대할 수 있다. 이러한 결과를 막기 위해서는 각각의 변수가 가지는 범위를 축소시켜줘야 한다. 바로 그것을 'Feature Scaling'이라고 부르는 것이다. 우리의 목적은 Feature Scaling을 통해서 각각의 변수가 가지는 범위를 -1 에서 1 사이로 만드는 것이다. 그렇지만 정확히 똑같이 -1 에서 1 사이로 맞추지는 않아도 된다. 약간 넘어가거나 그 범위에 못미치더라도 수긍 가능한 정도라면 문제가 발생하지 않는다. 그러나 너무 큰 차이가 나는 경우에는 다시 Feature Scaling을 할 필요가 생긴다. ex) 피쳐 스케일링을 잘못한 예: $-100 \leq x_{i} \ \leq 100$, $-0.00001 \leq x_{i} \ \leq 0.00001$
그렇다면 피쳐스케일링은 어떻게 해야할까? 바로 평균을 이용한 정규화 방식(Mean Normalization)이 있다. Mean Normalization은 $x_{i} $대신에
$x_{i} - \mu _{i}$ 를 써서 변수의 범위를 조정하는 것이다. 예컨대, 집값을 예측하기 위한 다중선형회귀에서 다음과 같은 변수들이 있다고 가정하자.

첫번째 변수는 바로 방의 크기를 나타내는 변수로, 변수의 초기 범위는 0에서 2000 피트제곱까지이다. 두번째 변수는 방의 개수를 나타내는 변수로 변수의 초기 범위는 1에서 5개이다. 두 변수를 Mean Normalization을 통해서 스케일링을 해본다면 다음과 같이 나타낼 수 있겠다.

첫번째 변수에다가는 초기 변수의 평균인 1000(2000 - 0 / 2)를 빼고 변수의 범위(2000-0) 대로 나눠주었다. 두번째 변수에는 초기 변수의 평균인 (5 - 1 / 2)를 빼주고 변수의 범위인 5 - 1으로 나눠주었다. 결과적으로 두 변수, 즉 Feature들은 -0.5에서 0.5 사이의 값을 갖게 되었다.
(4) 학습율(Learning Rate)
학습율은 경사하강법에서 얼마나 가파른 속도로 경사를 하강할 것인지에 영향을 끼치는 중요한 요소이다. 경사하강법이 잘 작동하고 있는지 판단하는 과정을 디버깅(Debugging)이라고 부른다. 학습율은 $\alpha$로 표현이 되는데, 이 학습율을 정하는 것은 머신러닝의 능력과 직결되기 때문에 디버깅을 통해서 적합한 학습율을 정해야 한다.
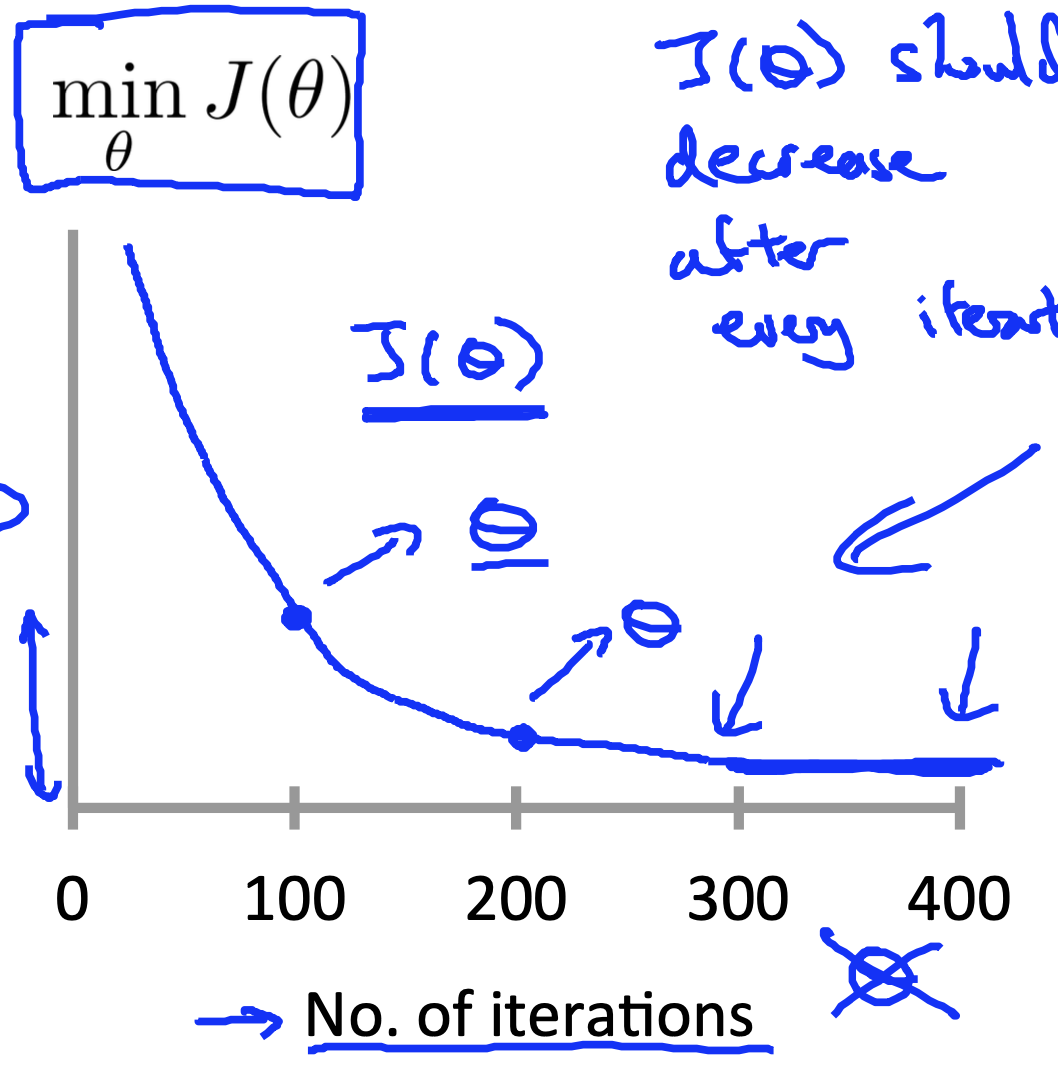
위 그래프와 같이 제대로 정해진 학습율은 매 반복에서 계속 우하향해야 한다. 만약 아래 그래프들과 같은 형태가 나온다면 더 작은 학습율을 찾아야 할 것이다.

위 세가지의 그래프는 모두 학습율이 커서 그래프가 하향하지 못하고 오버슈팅되는 현상이 발생한 것을 나타내고 있다.
그렇다면 과연 학습율은 무조건 작을수록 좋은 것일까? 그렇지는 않다. 왜냐하면 학습율이 필요 이상으로 작아지게 되면 더 많은 반복을 거듭하여야 하게 되고, 이는 머신의 성능을 저하할 뿐더러 결과를 도출하는데 지나치게 오랜 시간을 요구하게 된다.
결국 학습율이 지나치게 크면 매 반복에서 감소하지 않을 수 있고, 학습율이 지나치게 작으면 느리게 하강해서 결과가 도출되는 시간이 지연된다.
Andrew Ng 교수님은 다음과 같은 방법을 추천하신다. 먼저 학습율로 0.001을 설정해보고 느리게 하강한다면 0.003을 대입해보고, 그래도 느리다면 0.01을, 그래도 느리다면 0.03을 대입한다. 이런 식으로 증가시켜 나가는 방법을 추천하신다. 경험적으로 교수님께서 연구를 통해 체감하시고 사용법일수도 있겠지만, 감히 이런 방법을 택한 이유를 내 시각에서 분석해보자면 학습율이 낮아서 느리다고 10배씩 증가시키는 것보다 3배를 먼저 증가시켜 경사하강도의 형태가 Elbow Method와 근접하는지 확인한 후에 근접하지 않다면 10배를 곱하는 것이 훨씬 더 신중한 선택이라는 생각이 든다.
(5) 정규방정식(Normal Equation)
정규방정식은 손실함수를 최소화하는 또 다른 방법이다. 정규방정식에서는 $\theta$를 분석적으로 구할 수 있다. 정규방정식의 형태는 다음과 같다. $\theta = ( X^{T}X)^{-1}X^{T}y$. 여기서 $( X^{T}X)^{-1}$는 $X^{T}X$의 역행렬이다. 그래서 경사하강법과 정규방정식을 비교하면 다음과 같은 특징이 존재한다.

경사하강법에서는 학습율을 정해야 하고, 많은 반복이 필요하지만 변수의 개수가 클 때도 잘 작동한다는 특징이 있다. 정규방정식은 학습율을 정할 필요가 없고, 반복할 필요도 없지만, $O(n^3)$의 시간복잡도를 가지는 $( X^{T}X)^{-1}$를 계산해야 하기 때문에 변수의 개수가 클 때는 느려진다는 단점이 있다.
선형대수를 공부한 적이 있는 사람들은 이쯤에서 한 가지의 의문을 가질 수 있다. 바로 만약 $X^{T}X$의 역행렬이 존재하지 않는 경우에는 어떻게 정규방정식을 구하는지이다. 사실 현실세계에는 역행렬을 가지는 행렬보다 그렇지 않은 행렬들(singular matrix)이 더 많다. 그런 경우에는 불필요한 피처들을 제거하거나 몇 가지의 피처를 제거하여 사용할 수 있다. 여기서 불필요한 피처들이란 이미 존재하는 다른 피처들로 환원가능한 피처들이다. 즉 선형종속을 구성하는 피처들을 제거하는 것이다. 예컨대, 방의 크기가 피트제곱으로 표현되어 있는 피처는 방의 크기가 미터제곱으로 표현되어 있는 피처로 환원가능하다. 따라서 두가지의 피처는 서로 선형종속적이다. 그렇기 때문에 두가지 중 한가지를 제거해도 무방하다.
2. 선형대수학 복습(Linear Algebra Review)
Week 2 뒷 파트에서는 선형대수학 복습이 진행됐다. 역행렬과 행렬의 전치를 배웠다.
3. 스터디원과의 교류(Communication with Study mate)
스터디원인 승헌이와 함께 2주차 복습을 마치고 나서 이야기를 나누었다. 그 중에서 기억에 남는 것은 내가 말했던 것인데, 컴퓨터프로그래밍II 수업시간에 다른 데이터과학 분야에서 엘보우 메소드를 사용하는 것을 언급한 것이었다. K-Means 군집화에서도 학습율을 정할 때처럼 엘보우 메소드를 사용한다고 배웠다. K-Means 군집화에서는 오차제곱합(Error Sum of squares(SSE))의 그래프가 엘보우 메소드에 일치할 때, 적합한 K를 정할 수 있다고 한다. 급격히 감소하다가 완만하게 감소되도록 만드는 수를 채택한다는 점에서 K-Means 군집화와 강사하강법에서의 학습율이 유사해서 흥미로웠다.
다시 한번 더 여기서 사용되는 모든 자료들은 전부 Coursera - Machine Learning by Andrew Ng의 것임을 밝힘. (All the rights of this blog reserved to the Coursera - Machine Learning by Andrew Ng.)
'Machine Learning' 카테고리의 다른 글
| [Coursera - Machine Learning] 머신러닝 스터디 Week 1 (0) | 2022.05.23 |
|---|
