
| 일 | 월 | 화 | 수 | 목 | 금 | 토 |
|---|---|---|---|---|---|---|
| 1 | 2 | 3 | 4 | 5 | 6 | 7 |
| 8 | 9 | 10 | 11 | 12 | 13 | 14 |
| 15 | 16 | 17 | 18 | 19 | 20 | 21 |
| 22 | 23 | 24 | 25 | 26 | 27 | 28 |
| 29 | 30 |
- 최대공약수
- udemy
- sql
- AVLTree
- postgresql
- 자료구조
- 너비우선탐색
- BFS
- nullif
- 유데미
- timestamp
- C++
- COALESCE
- 개발
- CREATE TABLE
- Advanced SQL
- Machine Learning
- ML
- 시퀄
- pgadmin
- 백준
- 깊이우선탐색
- Andrew Ng
- 알고리즘
- coursera
- 과제
- 최소공배수
- 데이터베이스
- self join
- BST
- Today
- Total
승1's B(log n)
[Coursera - Machine Learning] 머신러닝 스터디 Week 1 본문
코세라의 Andrew Ng 교수님의 머신러닝 강의를 통해서 머신러닝에 입문하기로 했다. 앞으로 강의를 듣고 스터디를 하면서 매주 공부한 것들을 정리해보려고 한다.
Week 1 - Introduction
이번주 강의는 세 부분으로 구성되어 있었다.
1. 머신러닝에 대한 전반적인 설명(Introduction to Machine Learning)
2. 단일 회귀 분석(Linear Regression with One variable)
3. 선형대수 기초(Linear Algebra)
1. 머신러닝에 대한 전반적인 설명(Introduction to Machine Learning)
첫번째로 머신러닝에 대한 전반적인 설명에서는 머신러닝의 정의와 머신러닝의 종류에 대해서 배웠다.
(1) 머신러닝의 정의(Definition of Machine Learning)
역사적으로 처음 머신러닝의 정의로 알려진 것은 바로 Arthur Samuel(1959)에 의한 정의이다. Arthur Samuel은 머신러닝을 "Field of study that gives computers the ability to learn without being explicitly programmed."라고 정의했다. 번역하자면 "컴퓨터가 명시적으로 프로그래밍 되지 않았어도 스스로 배울 수 있는 능력을 갖게 해주는 영역의 연구"라고 볼 수 있다. 즉 컴퓨터가 스스로 배울 수 있는 능력을 키워주는 분야의 학문이라고 할 수 있겠다.
시간이 지나 1998년에는 Tom Mitchell이 정의한 머신러닝 정의가 많은 공감을 얻게 되었다. Tom Mitchell은 "A computer program is said to learn from experience E with respect to some task T and some performance measure P, if its performance on T, as measured by P, improves with experience E."라고 머신러닝의 정의를 내렸다. 번역하자면, "만약 컴퓨터 프로그램의 T에 관한 퍼포먼스가 P로 평가받고, E라는 경험으로 발전할 때, 컴퓨터 프로그램은 T라는 일에 대한 경험 E를 가지고, P라는 퍼포먼스를 낸다고 볼 수 있다."라고 볼 수 있다. 여기서 Tom Mitchell이 주목한 부분은 머신러닝의 구성 요소의 세분화인 것 같다. 머신러닝이 해결해야 할 문제를 T로 분류하고, 그것을 해결하기 위해서 컴퓨터에게 E라는 경험을 부여하고, P라는 퍼포먼스(성과)를 통해서 이 컴퓨터 프로그램이 얼마나 효과적인지를 판단하는 것이다.
Ex) Spam mail을 분류하는 것이 T일 때, E는 스팸 메일이 무엇인지를 컴퓨터에게 알려주는 것, P는 실제로 프로그램이 얼마나 Spam mail을 잘 분류하는지 정확도를 계산한 것.
(2) 머신러닝의 종류와 특징(Types of Machine Learning and its properties)
머신러닝의 종류는 크게 Supervised Learning, Unsupervised Learning, Reinforcement Learning으로 나눌 수 있다.
Supervised Learning은 정답이 있는 문제를 푸는 것을 말한다. 그렇기 때문에 Supervised Learning에서는 프로그램에 제공할 Data를 인간이 직접 labeling을 하게 된다. 예컨대, 고양이 사진에 고양이라고 labeling을 하고 강아지 사진에는 강아지라고 labeling을 하는 것이다.
이러한 Supervised Learning은 주로 Regression이나 Classification을 하는 데에 사용된다.

Regression을 통해서는 연속변수의 값을 예측할 수 있다. 위 강의에서 교수님께서 들어주신 예시는 평 수와 집 값의 데이터들을 제공하고 평 수에 맞는 집 값은 어느 것인지 예측하는 것이었다. 집 값은 discrete value가 아니라 continuous value이기 때문에 regression을 통해서 예측할 수 있다.
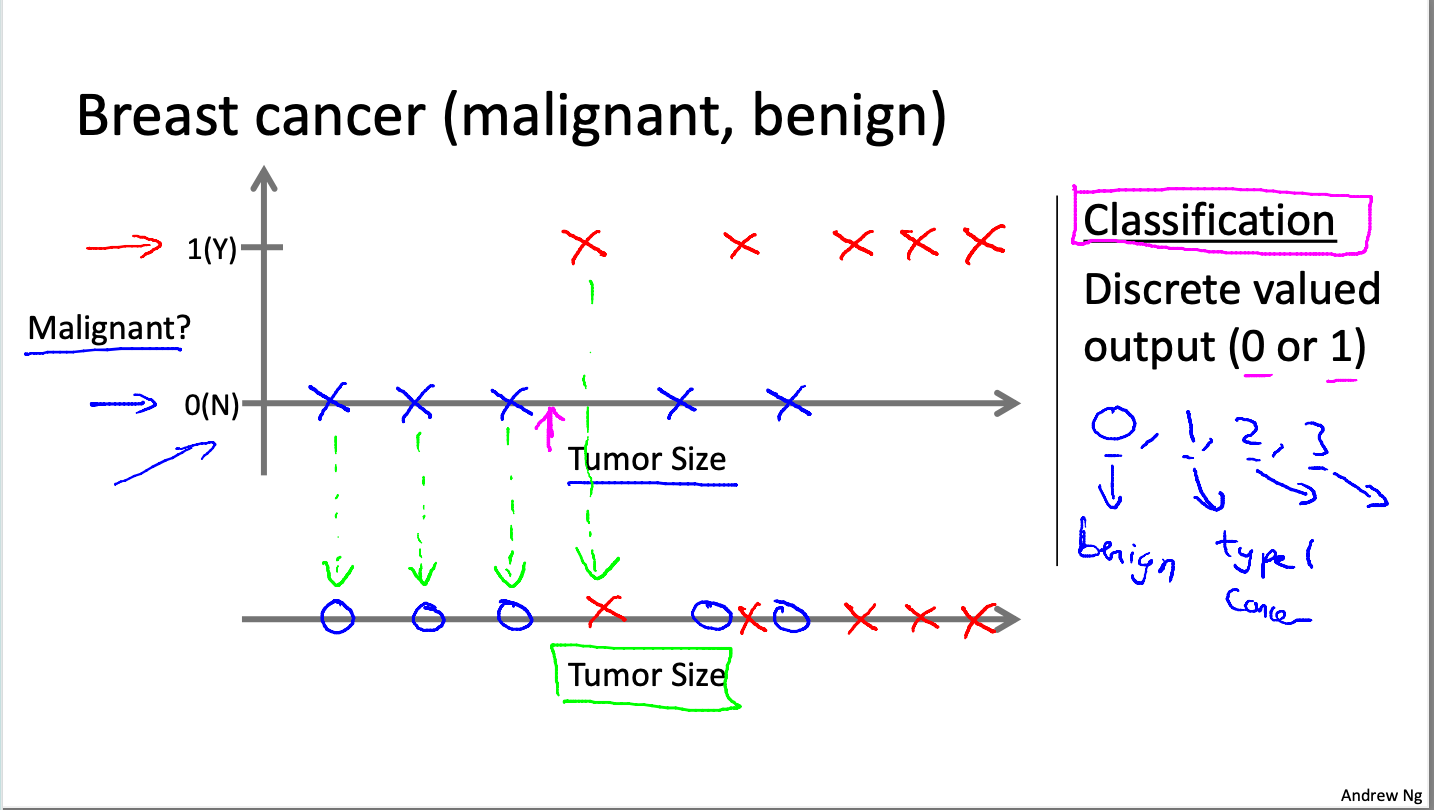
Classification은 이산변수들을 예측하는 데에 유용하게 사용된다. 0 아니면 1 같이 이산변수는 연속되지 않고 각각이 분리되어 있다. 교수님이 드신 예시는 종양이 크기를 통해서 유방암이 악성인지, 아니면 악성이 아닌지 classify하는 것이었다. 이러한 예측을 하기 위해서는 그동안의 경험을 바탕으로 프로그램에 종양의 크기와 악성 여부를 같이 제공해야 한다. 그렇기에 Supervised Learning으로 볼 수 있는 것이다.
Unsupervised Learning은 정답이 주어지는 문제를 해결하는 것이 아니라, 컴퓨터가 데이터를 받아서 스스로 숨겨진 구조를 찾는 것이다. Unsupervised Learning은 주로 Clustering을 해서 구조를 찾는다. 예시로는 사람들이 어떻게 연결되어있는지 파악하는 Social Network Analysis나 천체들의 구조를 파악하는 Astronomical data Analysis가 있다. 그 외에도 칵테일 파티 문제와 같이, 음성인식을 통해 자신에게 필요한 발화자의 목소리만을 따낼 수 있는 문제에서 사용될 수 있다.
Reinforcement Learning은 행동에 대한 보상을 제공해서 그 보상이 가장 극대화 될 수 있도록 하는 선택을 하게 만드는 머신러닝 기법이다.
이 Course에서는 주로 Supervised Learning에 집중해서 배울 것으로 보인다.
2. 단일 회귀 분석(Linear Regression with One Variable)
단일 회귀분석 파트에서는 비용 함수(Cost Function)에 대해서 배웠다. Supervised Learning에서 본인이 설정한 가설이 맞는지를 확인하기 위해서는 여러 test case들을 세우고 실험을 해야 한다. 그 과정에서 정확도를 계산하는 함수가 바로 Cost Function이다.

우리의 궁극적인 목적은 cost function을 최소화하여 세워놓은 가설의 정확도를 높이는 것이다. Cost Function의 구성은 이렇다. 가설을 통해서 계산한 값인 $h_{ \theta } ( x^{(i)} )$에서 $y^{i}$ 를 뺌으로써 오차를 계산한다. 그것들의 제곱의 합을 $\frac{1}{2m}$으로 나눠주면 Cost Function이 완성된다. 여기서 왜 $\frac{1}{2}$로 나눠주는지에 대해서는 교수님께서 후에 Gradient Descent 계산을 편하게 하기 위해서라고 설명해주셨다. 결국은 오차들의 제곱을 평균을 낸다는 점에서 squared error function이라고 불리기도 한다.
Gradient Descent는 cost function을 지속적으로 minimize해서 local minimum을 찾도록 하는 방법이다. Gradient Descent는 시작점이 매우 중요한데, 시작하는 좌표에 따라서 gradient descent의 결과가 다르게 나올 수 있기 때문이다.

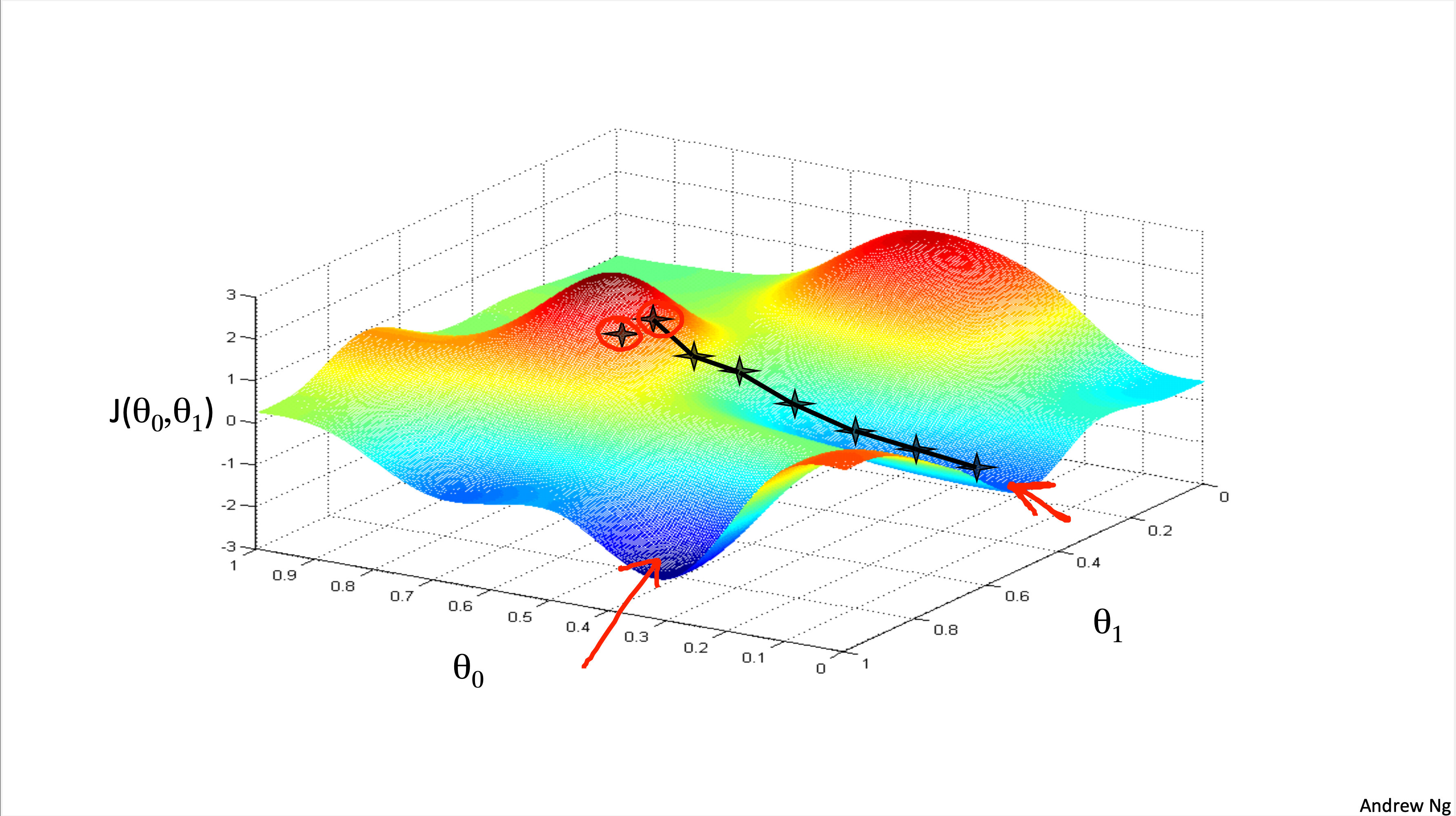
Gradient Descent의 알고리즘은 다음과 같다.

잠깐 수식에 사용된 terminology를 설명하고자 한다.
:=는 대입 연산자로 활용이 되고 있다. 일반적으로 C/C++ 등 여타 프로그래밍 언어에서는 = 이 대입 연산자로 활용되는 반면에 다르게 사용된다는 점이 특이했다. 되려 여기서 = 은 truth assertion을 위한 용도로 사용된다고 한다. 그리고 $\alpha$는 learning rate로 학습률로 정의되어 있다. 후방의 $\frac{ \partial }{ \partial \theta_{j} }J(\theta_0, \theta_1)$ 는 cost function을 미분한 것이다.
Gradient Descent를 계산하는 과정에서는 순서가 상당히 중요한데, Simultaneous하게 update를 해야 한다. 예컨대, 아래 사진과 같은 순서대로 계산해야 한다.

Learning rate에 관련해서는 $\alpha$가 너무 작으면 gradient descent의 속도가 저하되고, 반대로 $\alpha$가 너무 크면 gradient descent가 overshooting하는 경우가 발생할 수 있다고 한다. 그러나 도중에 Learning rate를 수정할 필요는 없다. 그 이유는 바로 $\frac{ \partial }{ \partial \theta_{j} }J(\theta_0, \theta_1)$가 minimum에 가까이 갈수록 기울기가 0에 수렴하기 때문에 작아지기 때문이다.
이와 같은 gradient descent 방식을 batch gradient descent라고 부른다. 각 단계에서 모든 training sets들을 사용하기 때문이다.
3. 선형대수 기초(Linear Algebra)
선형대수 파트에서는 행렬의 덧셈, 곱셈에 대한 기본적인 연산을 배웠다. 또한 몇 가지 성질을 배웠다. ex) 교환 법칙 성립 X, 결합 법칙 성립 O 그리고 inverse와 transpose에 대해서도 배웠다. 여기까지는 너무나도 기초적인 내용이라 자세한 설명은 생략하기로 함.
앞으로 어떤 내용을 배울지 점점 더 기대가 된다.
다시 한번 더 여기서 사용되는 모든 자료들은 전부 Coursera - Machine Learning by Andrew Ng의 것임을 밝힘. (All the rights of this blog reserved to the Coursera - Machine Learning by Andrew Ng.)
'Machine Learning' 카테고리의 다른 글
| [Coursera - Machine Learning] 머신러닝 스터디 Week 2 (0) | 2022.06.23 |
|---|
