
| 일 | 월 | 화 | 수 | 목 | 금 | 토 |
|---|---|---|---|---|---|---|
| 1 | 2 | 3 | 4 | 5 | 6 | 7 |
| 8 | 9 | 10 | 11 | 12 | 13 | 14 |
| 15 | 16 | 17 | 18 | 19 | 20 | 21 |
| 22 | 23 | 24 | 25 | 26 | 27 | 28 |
- 자료구조
- 유데미
- Andrew Ng
- pgadmin
- 너비우선탐색
- Advanced SQL
- 알고리즘
- C++
- nullif
- 과제
- postgresql
- udemy
- 시퀄
- COALESCE
- 최소공배수
- 백준
- ML
- BST
- timestamp
- 개발
- sql
- AVLTree
- CREATE TABLE
- coursera
- 최대공약수
- self join
- Machine Learning
- 데이터베이스
- 깊이우선탐색
- BFS
- Today
- Total
승1's B(log n)
SQL GROUP BY문과 JOIN문 배우기 본문
저번 포스팅에서는 SQL의 기초 문법을 배웠다면 이번에는 조금 더 심화된 구문들을 배워보고자 한다. 바로 GROUP BY문과 JOIN문이다.
GROUP BY문을 다루기 전에, 집계 함수들에 대해서 먼저 배워보자.
1) 집계함수
(1) AVG(column) : 선택한 열의 평균값을 구해주는 함수 / 소수점 이하의 수를 간편히 나타내고 싶다면 ROUND()함수와 같이 사용할 수 있다.
ex) ROUND(AVG(column), n) -> 평균값을 소수점 이하 n자리 수까지 구함.(n+1 자리수에서 반올림)
(2) COUNT(column) : 선택한 열의 행의 개수를 구해주는 함수
(3) MAX(column) : 선택한 열의 값 중에서 가장 큰 값을 구해주는 함수
(4) MIN(column) : 선택한 열의 값 중에서 가장 작은 값을 구해주는 함수
(5) SUM(column) : 선택한 열의 값의 총합을 구해주는 함수
이 집계함수들은 SELECT문이나 HAVING문에서만 사용할 수 있는데, HAVING문에서의 응용은 조금 이따가 확인해보도록 하자.
2) GROUP BY문
GROUP BY문은 카테고리 별로 열을 집계하기 위해 사용되는 구문이다.
수도코드를 먼저 알아보자.
SELECT category_col, AGG(data_col) FROM table GROUP BY category_col;
수도코드는 위와 같다. 집계할 기준이 되는 category_col을 선택하고, 어떤 값을 구하고 싶은지에 따라 다른 집계함수를 선택하고, GROUP BY문을 사용하여 category_col을 기준으로 값을 집계한다.
GROUP BY문을 사용할 때는 주의할 점이 있는데, 바로 GROUP BY문은 FROM문이나 WHERE문 뒤에 위치해야 한다는 것이다.
WHERE문을 사용한다는 것은 GROUP BY문을 적용하기 전에 특정 조건을 적용한 다음 카테고리 별로 집계하겠다는 것을 의미한다.
또 주의해야 할 점은 SELECT문에서 선택한 열 중, 집계함수가 적용된 열을 제외하고는 GROUP BY문에도 같이 적용해야 한다는 것이다. 예컨대, SELECT country, city, SUM(tourists) FROM travel GROUP BY country, city; 같은 식으로 말이다.
그리고 GROUP BY문을 사용할 때에는 WHERE문에서 집계함수를 사용해서는 안되면 이는 HAVING문에서 해야 할 일이다. GROUP BY문을 활용한 구문에서 순서대로 정렬한 값을 출력하고자 할 때에는 반드시 집계함수를 같이 사용해야 한다. 예컨대, SELECT country, city, SUM(tourists) FROM travel GROUP BY country, city ORDER BY SUM(tourists) DESC; 이런 식으로 말이다.
예시를 통해서 조금 더 잘 이해해보자.
두 명의 스태프 중 한 명에게 보너스를 주고 싶은데, 본인이 근무할 때 대여된 DVD들의 금액의 총합이 가장 큰 사람에게 주고자 한다. 그렇다면 둘 중 누가 받을 수 있을까?
사용할 수 있는 데이터베이스의 형태는 다음과 같다.

이 문제를 해결하기 위한 코드를 보자.
SELECT staff_id, SUM(amount) FROM payment
GROUP BY staff_id;위 코드를 실행시킨 결과는 다음과 같다.

결과를 통해서 추측할 수 있는 것은 바로 staff_id가 2인 직원이 staff_id가 1인 직원보다 더 매출실적이 좋다는 것이다. 고로 staff_id가 2인 직원이 보너스를 받는다고 생각할 수 있겠다.
3) HAVING문
HAVING문은 GROUP BY문과 함께 쓰이는 구문이다. WHERE문이 GROUP BY문이 실행되기 이전에 필터링을 한다면 HAVING문은 GROUP BY문이 실행되고 나서 필터링을 하는 역할을 수행한다.
수도코드를 살펴보자.
SELECT category_col, AGG(data_col)
FROM table
GROUP BY category_col
HAVING AGG(data_col) > 5;
WHERE문과 같이 HAVING문은 필터링을 하는 역할을 하다보니 비교연산자(=, !=, >, <, >=, <=)들을 사용하거나 IN이나 LIKE, ILIKE와 같은 다른 구문들과도 함께 사용할 수 있다.
다만 주의해야 할 점은 HAVING문에서 그냥 data_col 형태로 사용해서는 안되고, 앞서 SELECT문에서 사용했던 형태대로 집계함수와 함께 사용해야 한다는 것이다. 예컨대, 바로 위에서 살펴봤던 예시문제에서 스태프들의 매출 중 31000이 넘는 스태프의 기록만 보고 싶다고 생각하면 이런 식으로 구문을 작성해야 한다.
SELECT staff_id, SUM(amount) FROM payment
GROUP BY staff_id
HAVING SUM(amount) > 31000;그냥 HAVING amount > 31000라고 쓰면 안된다는 것이다. 왜냐하면 HAVING문은 GROUP BY문으로 이미 카테고리 별로 정리된 상태에서 필터링을 하는 것이기 때문이다.
4) AS문
이제 JOIN문으로 넘어가기 전에 AS문을 먼저 살펴보자. 그동안 SELECT문을 통해서 선택한 열들이 결과값으로 도출될 때 기존 열의 이름대로만 출력이 됐다면, 이제는 AS문을 활용해서 출력시 열의 이름을 바꿀 수 있다.
수도 코드는 다음과 같다.
SELECT column AS new_name FROM table;AS문을 사용하면 new_name을 기존 column 이름 대신 사용할 수 있게 된다.
추가적으로 알아야 할 것은 AS문은 쿼리의 맨 마지막에 실행된다는 것이다. 그렇기 때문에 WHERE이나 GROUP BY문에서는 AS문으로 인해 변경된 열의 이름을 사용하지 못한다는 것이다. 따라서 WHERE이나 GROUP BY문에서는 기존 열의 이름을 사용해야 한다는 것을 알 수 있다.
5) INNER JOIN문
이제부터 JOIN문에 대헤서 배워보도록 하자. JOIN문은 흔히 벤 다이어그램의 형태로 표현할 수 있다. 그리고 JOIN은 크게 INNER JOIN, FULL OUTER JOIN, LEFT OUTER JOIN, RIGHT OUTER JOIN 이렇게 네 가지로 나뉜다. 이름만 듣고서는 겁을 지레 먹을 수 있지만, 차근차근 설명해보도록 하겠다. 이해가 안된다면 반복적으로 보는 것이 중요할 것이다.
5번 섹션에서는 INNER JOIN에 대해서 살펴보자. 우선 INNER JOIN이란 Table A와 Table B가 있을 때 두 테이블의 교집합을 의미한다. 벤 다이어그램의 형태로 나타내면 다음과 같다.
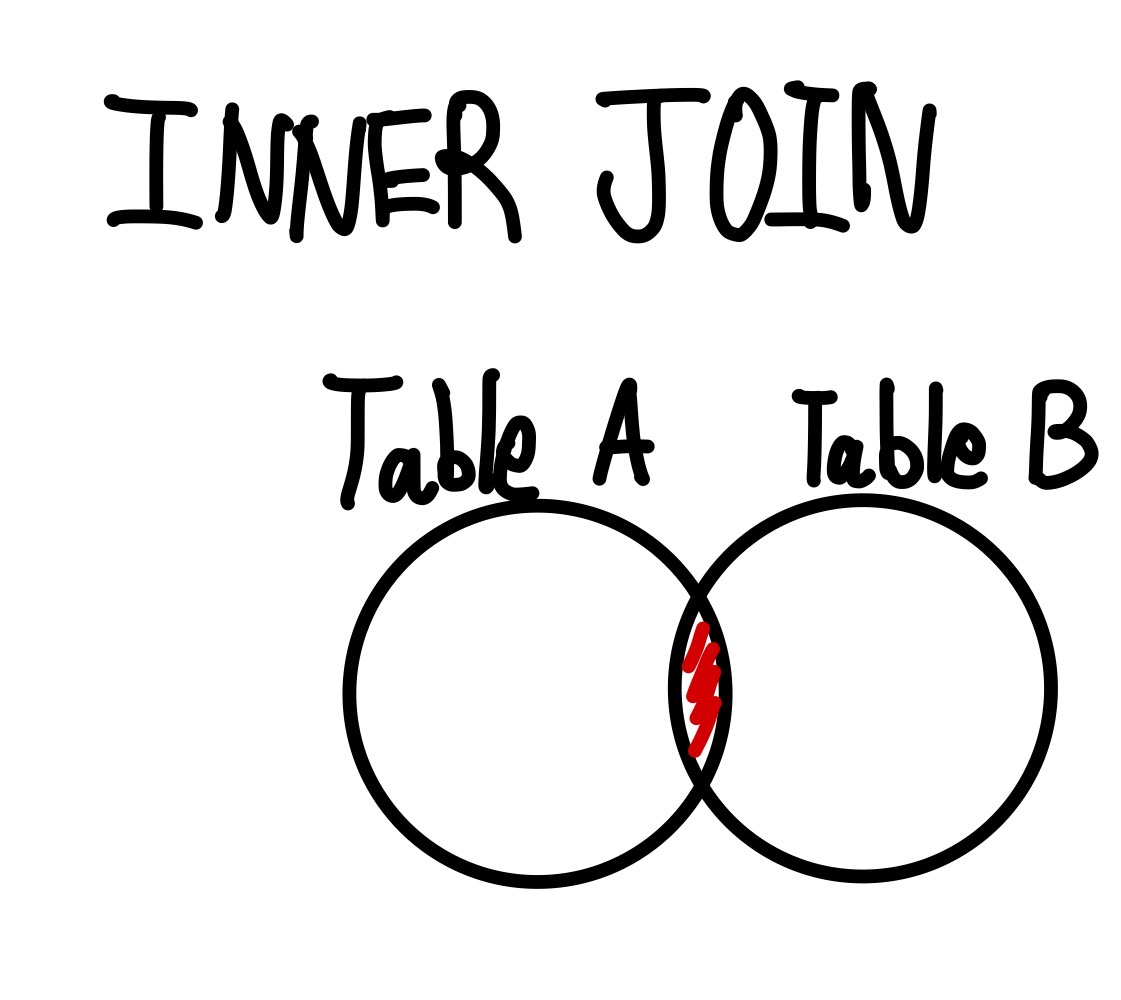
이 INNER JOIN을 이용하면 각 테이블에 모두 존재하는 열 혹은 데이터만을 다룰 수 있게 된다.
수도코드는 다음과 같다.
SELECT col1 FROM Table_A
INNER JOIN Table_B
ON Table_A.col_match = Table_B.col_match;우선 Table_A에서 구하고자 하는 열을 선택하고, INNER JOIN 뒤에 결합하고자 하는 Table_B를 써준 다음, ON 뒤에는 어떤 열에서 서로 동시에 갖고 있는 데이터를 추출할 것인지를 적는다.
이 설명만 들으면 아마 무슨 말인지 잘 모를 거라고 생각한다. 그렇다면 예시를 들어 설명을 해보도록 하겠다.
우선 payment 테이블에 어떤 열들이 있는지 한 번 보도록 하자.
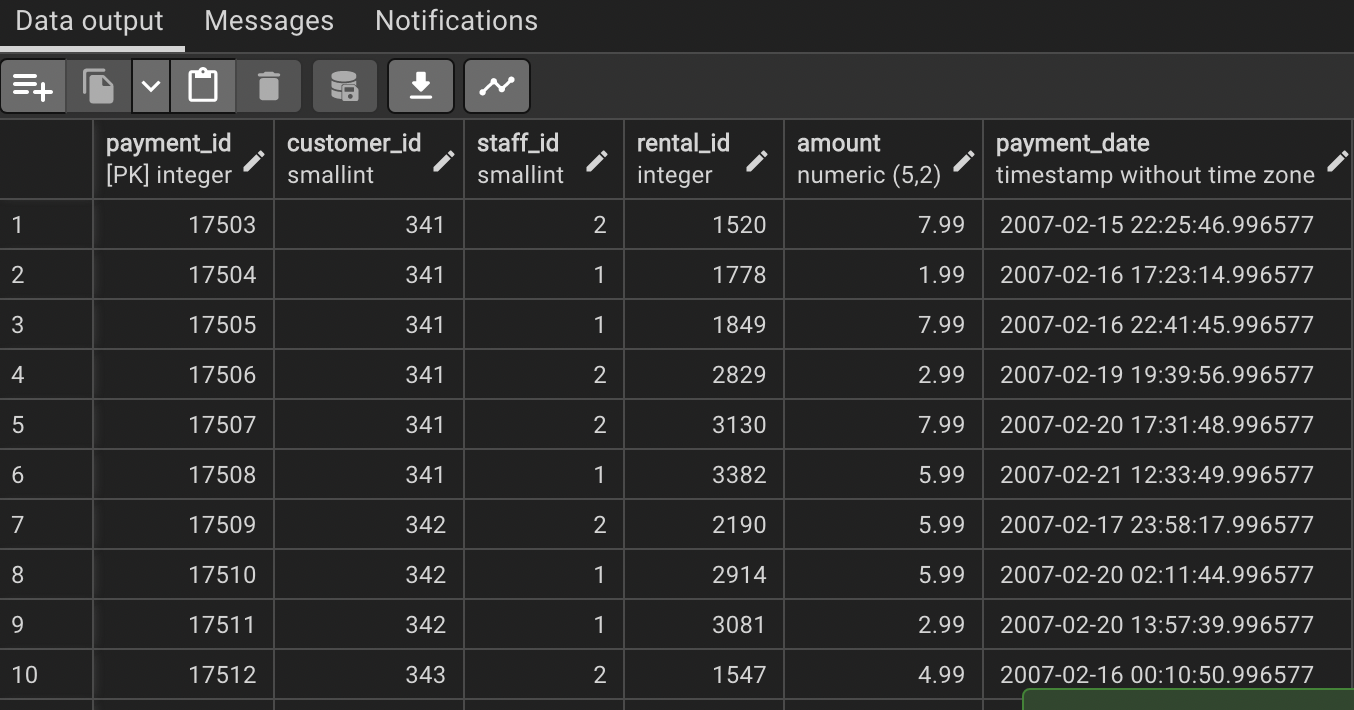
그리고 customer 테이블에는 어떤 열들이 있는지도 살펴보자.

두 테이블에 공통적으로 있는 열은 customer_id가 있다. 그렇다면 두 테이블에 모두 존재하는 고객의 payment_id와 customer_id를 추출하여 customer_id의 오름차순대로 정렬해보자.
코드를 작성하기에 앞서 테이블에 대한 간략히 설명을 하자면, payment 테이블은 결제를 한 고객의 정보들을 수집해놓은 테이블이고, customer 테이블은 결제 이력과 상관 없이 등록되어 있는 고객의 정보가 수집되어있는 테이블이다. 또한 payment 테이블에는 한 고객이 결제를 여러번 한 경우 결제를 할 때마다 그 고객의 로그가 남는다. 고로, 같은 customer_id를 가진 값들이 한 개 이상 존재할 수 있다. 반면에 customer 테이블에는 각 행마다 customer_id가 고유하다. 그렇기에 두 테이블 중 한 쪽에만 속한 고객이 있을 수도 있고(고객 등록만 하고 결제를 안한 사람의 경우), 양쪽 모두에 속한 고객이 있을 수 있는 것이다(고객 등록도 하고, 결제도 한 사람의 경우).
이제 천천히 코드를 작성해보자.
구하고자 하는 것이 두 테이블에 모두 존재하는 customer_id에 상응하는 payment_id를 구하는 것이므로 우선 이렇게 적을 수 있다.
SELECT payment.customer_id, payment_id FROM payment만약 customer 테이블에서 선택하고 싶은 열이 있을 때는 SELECT문 뒤에 같이 써도 괜찮다. 참고로 두 열 모두에 중첩되는 이름이 있는 경우에는 테이블.열의 형태로 써주는 것이 좋다.
그 다음 두 테이블에 모두 존재하는 customer_id 열을 통해서 customer_id의 숫자 중에서 두 테이블에 모두 존재하는 고객의 payment_id를 추출해보자.
SELECT payment.customer_id,payment_id FROM payment
INNER JOIN customer
ON payment.customer_id = customer.customer_id
ORDER BY payment.customer_id ASC;INNER JOIN 뒤에는 customer 테이블을 적어주고, ON 뒤에는 = 식의 형태로 두 테이블에 모두 존재하는 customer_id 들을 추출했다.
마지막 조건인 customer_id의 오름차순대로 정렬도 시켜줬다.
자 이제 그럼 결과를 살펴보자.
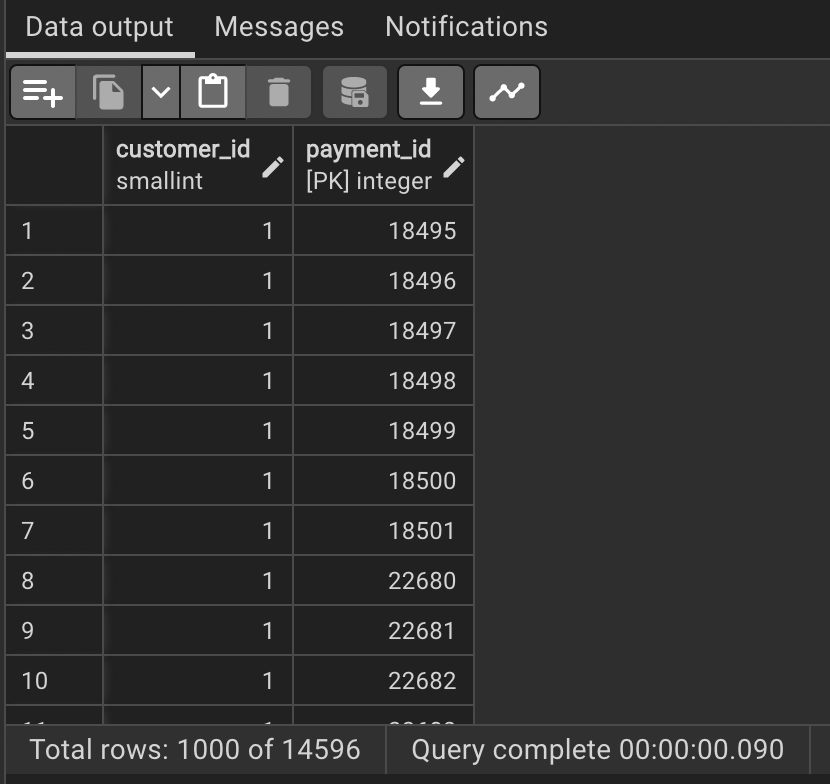
이런 식으로 결제를 한 번도 하지 않은 고객을 제외한 고객 아이디와 결제 아이디를 추출할 수 있다.
그렇다면 이제 INNER JOIN의 성질에 대해서도 살펴보자.
(1) INNER JOIN의 벤 다이어그램에서 볼 수 있듯이 서로 대칭이기 때문에, 테이블을 쓰는 순서를 바꿔도 유효하다.
즉, 이런 식으로 써도 된다는 것이다.
SELECT col1 FROM Table_B
INNER JOIN Table_A
ON Table_A.col_match = Table_B.col_match;물론 ON 뒤에 있는 수식의 순서를 뒤바꾸어도 괜찮다.
결국은 두 테이블의 교집합을 구하는 것이기 때문에, Table_A에 Table_B를 조인하던, Table_B에 Table_A를 조인하던 같은 결과를 갖게 되는 것이다.
(2) 만약 열의 이름이 고유하지 않는 경우에는 어떤 테이블에서 그 열을 불러왔는지를 명확히 표시하기 위해 테이블.열의 형태로 표시해야 한다.
(3) SQL에서는 INNER JOIN 대신 JOIN을 사용할 수도 있다. 즉, JOIN만 적었을 경우 INNER JOIN으로 인식한다는 것이다.
추가적으로, JOIN을 연속적으로 사용할 수도 있다. 수도코드를 남겨보겠다.
SELECT columns_1 FROM Table_A
INNER JOIN Table_B
ON Table_A.match_col_1 = Table_B.match_col_1
INNER JOIN Table_C
ON Table_A.match_col_2 = Table_C.match_col_2이정도로 INNER JOIN에 대한 설명을 마무리 하고 이제 FULL OUTER JOIN으로 넘어가보자.
(6) FULL OUTER JOIN
FULL OUTER JOIN은 합집합을 의미한다. 이해를 돕기 위해 벤 다이어그램을 그려보면 다음과 같다.

FULL OUTER JOIN문을 사용하면 두 테이블에 동시에 존재하는 데이터 이외에도 출력할 수 있게 된다.
수도코드로 표현해보자.
SELECT * FROM Table_A
FULL OUTER JOIN Table_B
ON Table_A.col_match = Table_B.col_match;이해가 잘 안된다면 다음 예시를 통해서 잘 생각해보자.
우선 두 개의 테이블이 존재한다고 생각해보자. 첫번째 테이블인 registrations 테이블에는 등록 아이디를 나타내는 reg_id와 등록자의 이름을 저장한 name 열이 존재하고, 두번째 테이블인 logins 테이블에는 로그인 아이디를 나타내는 log_id와 로그인한 사람의 이름을 저장한 name 열이 존재한다.
registrations에 저장된 이름은 Andrew, Bob, Charlie, David이고, logins에 저장된 이름은 Xavier, Andrew, Yolanda, Bob이다. 이 두 테이블을 name을 기준으로 FULL OUTER JOIN을 해보도록 하겠다.
코드는 다음과 같다.
SELECT * FROM logins
FULL OUTER JOIN registrations
ON registrations.name = logins.name
과연 결과는 어떨까?

두 테이블에 있는 내용이 하나로 합쳐졌다. 우선 기준이 되는 테이블이 위 코드에서는 logins였으므로 logins의 log_id와 name이 먼저 왼쪽에 출력이 되고, 오른쪽에는 registrations 테이블의 name이 왼쪽의 logins의 name과 일치하는 것들은 같은 행에 적어주고, 같은 이름이 없는 데이터들은 옆에 null 값을 삽입해준다. 이게 바로 FULL OUTER JOIN의 역할이다.
두 테이블에 동시에 존재하는 값들은 같이 적어주고, 동시에 존재하지 않는 값들은 대신에 null을 넣어주는 것이다.
그렇다면 빈 곳에 null을 넣어주는 FULL OUTER JOIN의 성질을 이용한다면 서로에게 고유한 데이터들도 구할 수 있지 않을까? 정답이다. 그럴 때는 앞서 배웠던 WHERE문을 이용하면 된다. 참고로, WHERE문은 JOIN이 되고 난 후에 작동한다.
수도코드를 확인해보자.
SELECT * FROM Table_A
FULL OUTER JOIN Table_B
ON Table_A.col_match = Table_B.col_match
WHERE Table_A.col_match IS NULL OR Table_B.col_match IS NULL;
이 수도코드를 위에서 확인했던 예제에도 적용하면 다음과 같이 적을 수 있다.
SELECT * FROM logins
FULL OUTER JOIN registrations
ON registrations.name = logins.name
WHERE registrations.name IS NULL OR logins.name IS NULL결과는 다음과 같이 도출된다.

각 테이블에 존재하는 고유한 이름만이 출력되는 것을 확인할 수 있다.
이쯤되면 이런 생각이 들 수도 있다. '각 테이블에 존재하는 고유한 이름들을 출력하는 거면, INNER JOIN과 정반대되는 개념이 아닌가?' 맞다. 방금 적은 수도코드의 벤 다이어그램은 다음과 같이 그릴 수 있다.
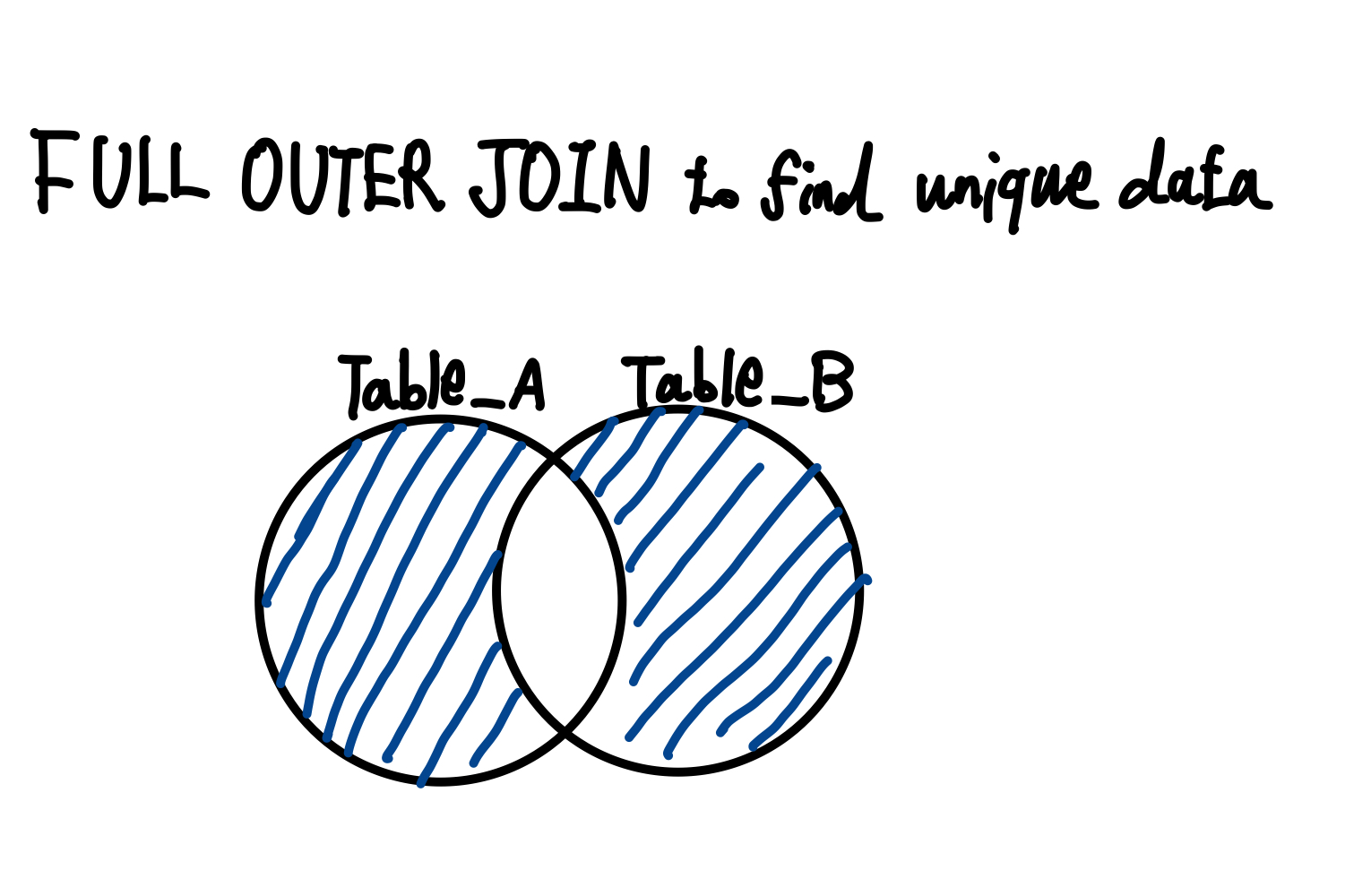
FULL OUTER JOIN의 성질도 정리해보자.
(1) INNER JOIN처럼 서로 대칭이기 때문에 적는 순서를 바꿔써도 문제가 없다. 다만, SELECT * FROM 뒤에 적는 테이블이 더 먼저 출력된다.
(2) WHERE 문을 통해서 각 테이블에 고유한 정보만을 추출할 수도 있다.
7) LEFT OUTER JOIN, RIGHT OUTER JOIN
이제 LEFT OUTER JOIN과 RIGHT OUTER JOIN에 대해서 배워보자.
LEFT OUTER JOIN은 왼쪽에 있는 테이블에 있는 데이터를 출력하는데, 다른 테이블과 교집합인 것도 같이 출력한다는 의미이다. 벤 다이어그램으로 나타내보자.
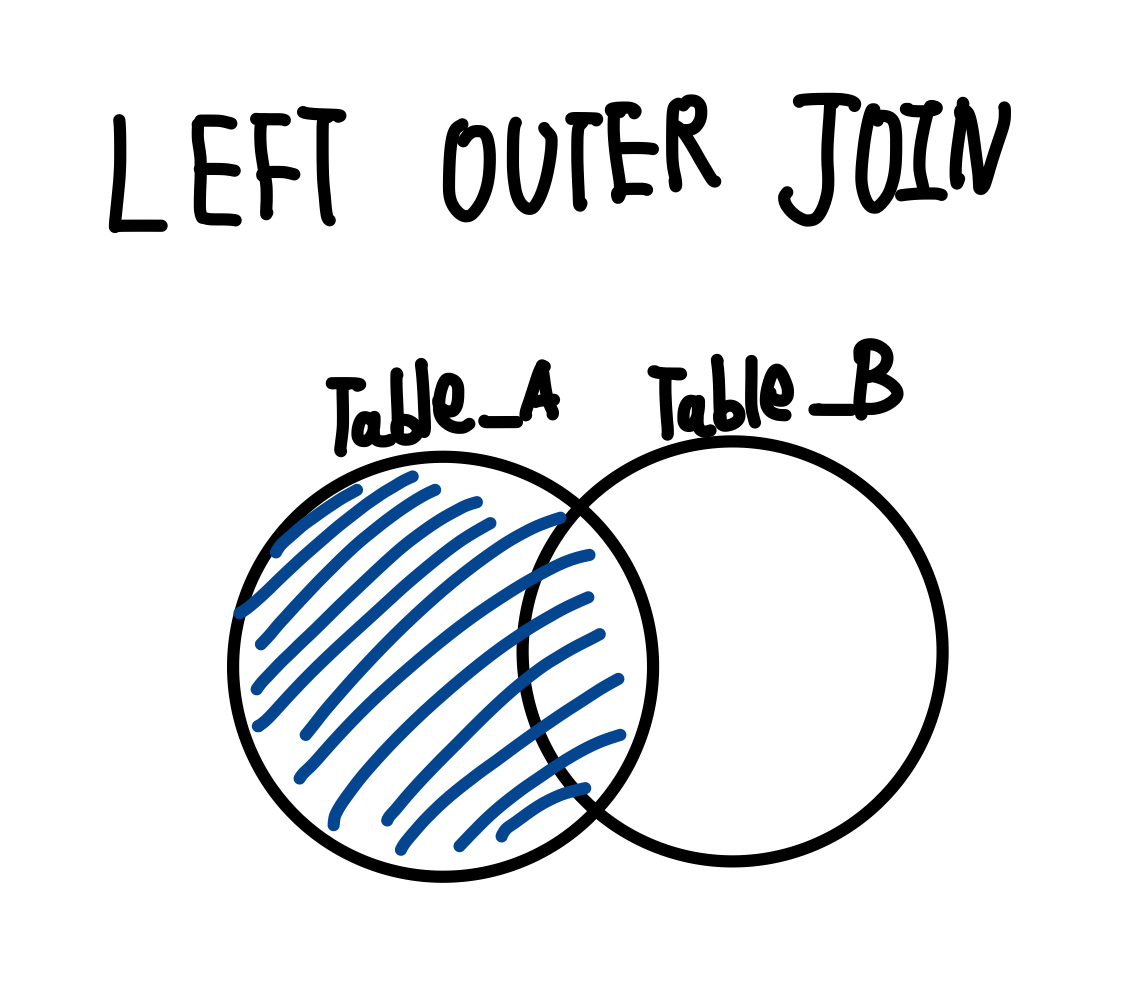
수도코드로는 어떻게 표현될까? 다음과 같다.
SELECT * FROM Table_A
LEFT OUTER JOIN Table_B
ON Table_A.col_match = Table_B.col_match;벤 다이어그램에서 볼 수 있듯이, LEFT OUTER JOIN은 비대칭이다. 따라서 쓰는 순서가 중요해진다. 수도코드를 보면 Table_A가 먼저 선택되는 것을 알 수 있다. 즉, 먼저 FROM을 통해서 선택되는 테이블이 왼쪽에 위치하게 되는 것이고, 뒤에 LEFT OUTER JOIN 키워드를 통해서 나오는 테이블은 오른쪽에 있는 테이블이 되는 것이다. 그렇기에 순서에 유의해야 한다.
FULL OUTER JOIN에서 들었던 예시에서 logins 테이블을 왼쪽에 두는 LEFT OUTER JOIN을 실행한다고 해보자.
코드는 다음과 같다.
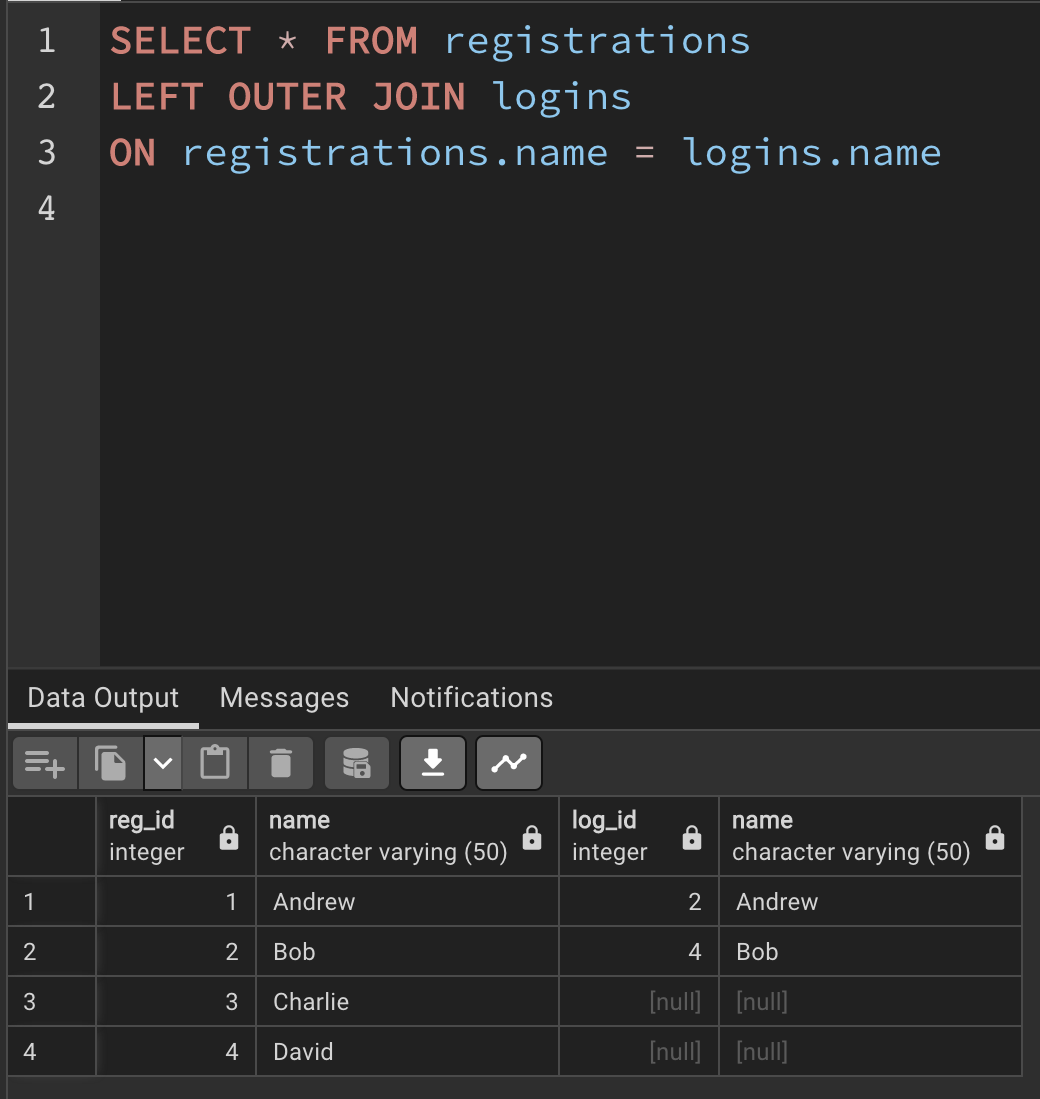
SELECT * FROM logins
LEFT OUTER JOIN registrations
ON logins.name = registrations.name결과는 다음과 같이 도출된다.

왼쪽에 있던 logins 테이블의 정보는 모두 출력된 것을 확인할 수 있다. 그럼 이번에는 반대로 registrations 테이블을 왼쪽에 두고 LEFT OUTER JOIN을 해보자.
코드는 다음과 같다.
SELECT * FROM registrations
LEFT OUTER JOIN logins
ON registrations.name = logins.name결과는 다음과 같다.

이번에는 왼쪽에 있는 테이블이 registrations이 된 것이다. 그러자 registrations 테이블에 있는 정보들은 모두 출력됐다.
혹시나 궁금할 것 같아서 ON 뒤에 있는 순서도 의미가 있는지 확인해보았다. 즉 ON registations.name = logins.name이나 ON logins.name = registrations.name의 차이가 있는지 말이다. 결론부터 말하자면 차이가 없다. 따라서 신경쓰지 않아도 된다.

FULL OUTER JOIN에서 각 테이블에 고유한 데이터들을 구했던 것처럼, LEFT OUTER JOIN에서는 왼쪽 테이블에 고유한 데이터를 추출할 수 있다. 마찬가지로 WHERE문을 사용하면 된다. 코드를 통해 알아보자.
SELECT * FROM Table_A
LEFT OUTER JOIN Table_B
ON Table_A.col_match = Table_B.col_match
WHERE Table_B.col_match IS NULL주의해야할 점은 마지막 WHERE문에서 다루는 테이블이 왼쪽에 있는 테이블이 아니라 오른쪽에 있는 테이블이어야 한다는 것이다. 왜냐하면 왼쪽에 있는 테이블의 값은 null 없이 모두 추출이 되기 때문에 오른쪽에 있는 테이블의 값을 확인하는 것이 맞기 때문이다.
RIGHT OUTER JOIN은 LEFT OUTER JOIN을 거꾸로 뒤집은 것이라고 생각하면 된다. 오른쪽 테이블에 있는 값들은 모두 추출되는 특징을 가진다. 수도코드를 다음과 같이 작성할 때, 벤 다이어그램은 다음과 같이 그릴 수 있다.
SELECT * FROM Table_A
RIGHT OUTER JOIN Table_B
ON Table_A.col_match = Table_B.col_match

LEFT OUTER JOIN과 RIGHT OUTER JOIN의 특징을 알아보자.
(1) 비대칭이므로 쓰는 순서가 중요하다. *FROM 뒤에 나오는 테이블이 왼쪽 테이블이고, JOIN문 뒤에 나오는 테이블이 오른쪽 테이블이다.
(2) LEFT OUTER JOIN은 LEFT JOIN으로 줄여적을 수 있음. 마찬가지로 RIGHT OUTER JOIN은 RIGHT JOIN으로 줄여적기 가능.
(3) WHERE문을 통해서 왼쪽 혹은 오른쪽 테이블에 고유한 정보를 추출할 수 있다.
8) UNION 연산자
UNION 연산자는 SELECT문을 통해 추출한 값을 위아래로 이어주는 역할을 한다. 고로, 추출한 값들이 서로 논리적으로 맞아야 한다. 예시를 들어보자.

두 개의 테이블이 있다고 하자. 하나는 정규직 직원들의 명단을 관리하는 테이블이고, 다른 하나는 계약직 직원들의 명단을 관리하는 테이블이다. 계약직 직원 중 Barbara와 Cole을 정규직 직원으로 편입하려고 한다. 이럴 때 명단을 UNION 연산자를 통해 합칠 수 있다. UNION 연산자를 통해 합치면 다음과 같은 모습을 띠게 된다.

위 예시를 통해서 볼 수 있듯이 어느정도 형태가 맞고 논리적인 이유가 있을 때 UNION 연산자를 사용할 수 있다.
그럼 UNION 연산자를 활용한 수도코드를 살펴보자.
SELECT columns FROM Table_A
UNION
SELECT columns FROM Table_B만약 여러 개의 테이블을 합치고 싶다면 UNION을 연속적으로 계속 사용해도 좋다. 이런 식으로 말이다. SELECT - UNION - SELECT - UNION - ....
그리고 합친 테이블을 정렬하고 싶다면 뒤에 ORDER BY 기준이 되는 열 ASC(or DESC)를 적으면 된다.
이상으로 SQL의 GROUP BY문과 JOIN문 정리를 마무리 하도록 하겠다.
'Database' 카테고리의 다른 글
| SQL 조건식과 프로시저 (0) | 2022.10.30 |
|---|---|
| SQL 테이블 만들기 (0) | 2022.10.27 |
| SQL 고급 명령어 (0) | 2022.10.24 |
| SQL 구문 기초 정리 (0) | 2022.08.31 |


