
| 일 | 월 | 화 | 수 | 목 | 금 | 토 |
|---|---|---|---|---|---|---|
| 1 | 2 | |||||
| 3 | 4 | 5 | 6 | 7 | 8 | 9 |
| 10 | 11 | 12 | 13 | 14 | 15 | 16 |
| 17 | 18 | 19 | 20 | 21 | 22 | 23 |
| 24 | 25 | 26 | 27 | 28 | 29 | 30 |
- 최대공약수
- 최소공배수
- ML
- nullif
- 너비우선탐색
- COALESCE
- Machine Learning
- 자료구조
- 백준
- 유데미
- 데이터베이스
- BST
- self join
- 깊이우선탐색
- sql
- 알고리즘
- 개발
- CREATE TABLE
- postgresql
- pgadmin
- coursera
- C++
- 과제
- Andrew Ng
- AVLTree
- 시퀄
- BFS
- udemy
- timestamp
- Advanced SQL
- Today
- Total
승1's B(log n)
C++ STL 정리 본문
1. 컨테이너
1) vector
#include <iostream>
#include <vector>
using namespace std;
int main(void){
//Constructor
vector<int> var1; //원하는 <자료형> 만큼의 벡터 생성
vector<int> var2(10); //크기가 10인 벡터 생성
vector<int> var3(10, 5); //크기가 10인 벡터 생성 후 5로 초기화
vector<int> var4(var3.begin(), var3.end()); //var3 벡터를 iterator를 이용해서 복사. begin부터 end 직전까지 복사
vector<int> var5(var3); //var3 벡터를 복사
//Iterators
vector<int>::iterator IT;
IT = var1.begin(); //var1의 첫번째 요소의 주소 가리킴, ++할수록 마지막 요소와 가까워짐
IT = var1.end(); //var1의 마지막 요소의 다음 주소 가리킴
vector<int>::reverse_iterator RIT;
RIT = var1.rbegin(); //reverse된 begin이므로 var1의 마지막 요소의 다음 주소 가리킴, ++할수록 첫번째 요소와 가까워짐
RIT = var1.rend(); //reverse된 end이므로 var1의 첫번째 요소의 주소 가리킴
vector<int>::const_iterator CIT;
CIT = var1.cbegin(); //첫번째 요소의 주소를 상수로 반환해서 값의 변경 방지
CIT = var1.cend(); //마지막 요소의 다음 주소를 상수로 반환해서 값의 변경 방지
vector<int>::const_reverse_iterator CRIT;
CRIT = var1.crbegin(); //마지막 요소의 다음 주소를 상수로 반환해서 값의 변경 방지
CRIT = var1.crend(); //첫번째 요소의 주소를 상수로 반환해서 값의 변경 방지
//Print
for(vector<int>:: iterator it = var5.begin(); it != var5.end(); it++) //iterator를 활용한 벡터 요소 출력
cout << *it << endl;
for(int i = 0; i < var1.size(); i++)
cout << var1[i] << endl; //배열식으로 벡터 요소 출력
//Capacity
var1.empty(); //비어 있으면 1, 비어 있지 않으면 0 반환(bool 값)
var1.size(); //저장되어 있는 원소들의 개수를 반환하는 함수
var1.max_size(); //저장할 수 있는 최대 원소 개수 반환;capacity와는 다름
var1.capacity(); //메모리 추가 할당 없이 저장할 수 있는 원소들의 개수를 반환하는 함수
var1.resize(15, 10); //벡터의 크기를 15으로 재설정하고, 남는 공간의 요소는 10으로 추가함.
var1.reserve(15); //벡터의 capacity를 15로 설정
var1.shrink_to_fit(); //벡터의 capacity를 size에 맞게 축소
//Element Access
var1[1]; //index가 1인 요소에 접근
var1.at(1); //index가 1인 요소에 접근
var1.front(); //맨 앞 요소 반환, 값 변경 가능
var1.back(); //맨 뒤 요소 반환, 값 변경 가능
int* A = var1.data(); //맨 앞 요소의 주소값 반환, A++, ++A, A[2] == *(A+2) 등을 활용해서 다른 요소에 접근하여 값 변환 가능
//Modifiers
var1.assign(var2.begin(), var2.end()); //iterator를 이용해서 var1에 var2 복사
var1.assign(10, 5); //var1에 5를 10만큼 할당
var1.push_back(15); //벡터 맨 뒤에 15 추가
var1.pop_back(); //마지막 요소 삭제
var1.insert(IT, 5); //iterator를 통해서 삽입할 위치를 지정하고 5를 삽입
var1.insert(++IT, var2.begin(), var2.end()); //++IT 자리에 var2의 begin부터 end 전까지의 값을 삽입
var1.erase(IT, IT+2); //IT부터 IT+2의 전까지 요소 삭제, 즉 IT, IT+1 요소 삭제
var1.swap(var2); //var1과 var2를 swap
var1.clear(); //요소 값들을 전부 삭제
var1.emplace(IT, 100); //IT 자리에 100을 추가
var1.emplace_back(200); //맨 뒤에 200을 추가
return 0;
}헷갈리는 포인트 짚기!
(1) reserve(N)와 resize(N, M)의 차이 : 얼핏보기엔 두 메서드가 비슷해보이지만 하는 일은 다르다. reserve()는 벡터의 size를 유지하고, 괄호 안의 숫자인 N으로 capacity를 재설정한다(기존 capacity보다 더 커야 함). 반면에 resize()는 값이 M인 요소들을 추가시켜 size가 N이 되도록 증가시키고, capacity는 유지하거나 모자랄 경우 다른 방식으로 증가시킨다(ex. doubling 등)
이해를 돕기 위한 참고 코드:
#include <iostream>
#include <vector>
using namespace std;
int main()
{
vector<int> var1(5, 5); //크기가 5인 var1 벡터 생성 후 5로 초기화
vector<int> var2(6, 5); //크기가 6인 var2 벡터 생성 후 5로 초기화
cout << "print var1 :" << endl;
for(int i = 0; i < var1.size(); i++)
cout << var1[i] << " "; //var1 벡터 요소 출력
cout << "" << endl;
cout << "var1 size : " << var1.size() << endl; //var1의 size 출력
cout << "var1 capacity : " << var1.capacity() << endl; //var1의 capacity 출력
cout << "print var2 : " << endl;
for(int i = 0; i < var2.size(); i++)
cout << var2[i] << " "; //var2 벡터 요소 출력
cout << "" << endl;
cout << "var2 size : " << var2.size() << endl; //var2의 size 출력
cout << "var2 capacity : " << var2.capacity() << endl; //var2의 capacity 출력
cout << "" << endl;
cout << "!!!reserve var1 to 7!!!" << endl;
var1.reserve(7); //var1에 reserve(7) 함수 사용
cout << "print var1 :" << endl;
for(int i = 0; i < var1.size(); i++)
cout << var1[i] << " "; //var1 벡터 요소 출력
cout << "" << endl;
cout << "var1 size : " << var1.size() << endl; //var1의 size 출력
cout << "var1 capacity : " << var1.capacity() << endl; //var1의 capacity 출력
cout << "!!!resize var2 to 7 with 10!!!" << endl;
var2.resize(7, 10); //var2에 resize(7, 10) 함수 사용
cout << "print var2 : " << endl;
for(int i = 0; i < var2.size(); i++) //var2 벡터 요소 출력
cout << var2[i] << " ";
cout << "" << endl;
cout << "var2 size : " << var2.size() << endl; //var2의 size 출력
cout << "var2 capacity : " << var2.capacity() << endl; //var2의 capacity 출력
return 0;
}Output :

(2) insert()와 emplace()의 차이 : 두 메서드 모두 벡터의 특정한 위치에 원소를 추가하는 역할을 수행한다. 차이점은 insert()의 경우 삽입할 객체를 만들어서 전달하고 내부에서도 임시객체를 만들어서 삽입하기 때문에 불필요한 연산들이 발생하지만, emplace는 내부에서 생성, 삽입을 하기 때문에 생성자와 소멸자를 한 번씩만 부르게 되고 결국 불필요한 참조를 최소화하므로 더 효율적이다. 그리고 emplace()는 한 번 호출할 때 하나의 요소만은 삽입할 수 있는 것에 반하여 insert()는 여러개의 요소를 삽입할 수 있다는 차이점도 있다. 일반적으로 더 효율적인 사용을 위해서는 insert()보다는 emplace()를, push_back() 대신에 emplace_back()을 사용하는 것을 추천한다.
참고 자료 : https://shaeod.tistory.com/630
2) stack
스택은 LIFO(Last In First Out)를 기반으로 하는 자료구조이다. 즉, 가장 나중에 들어온 것이 먼저 제거되는 것이다.
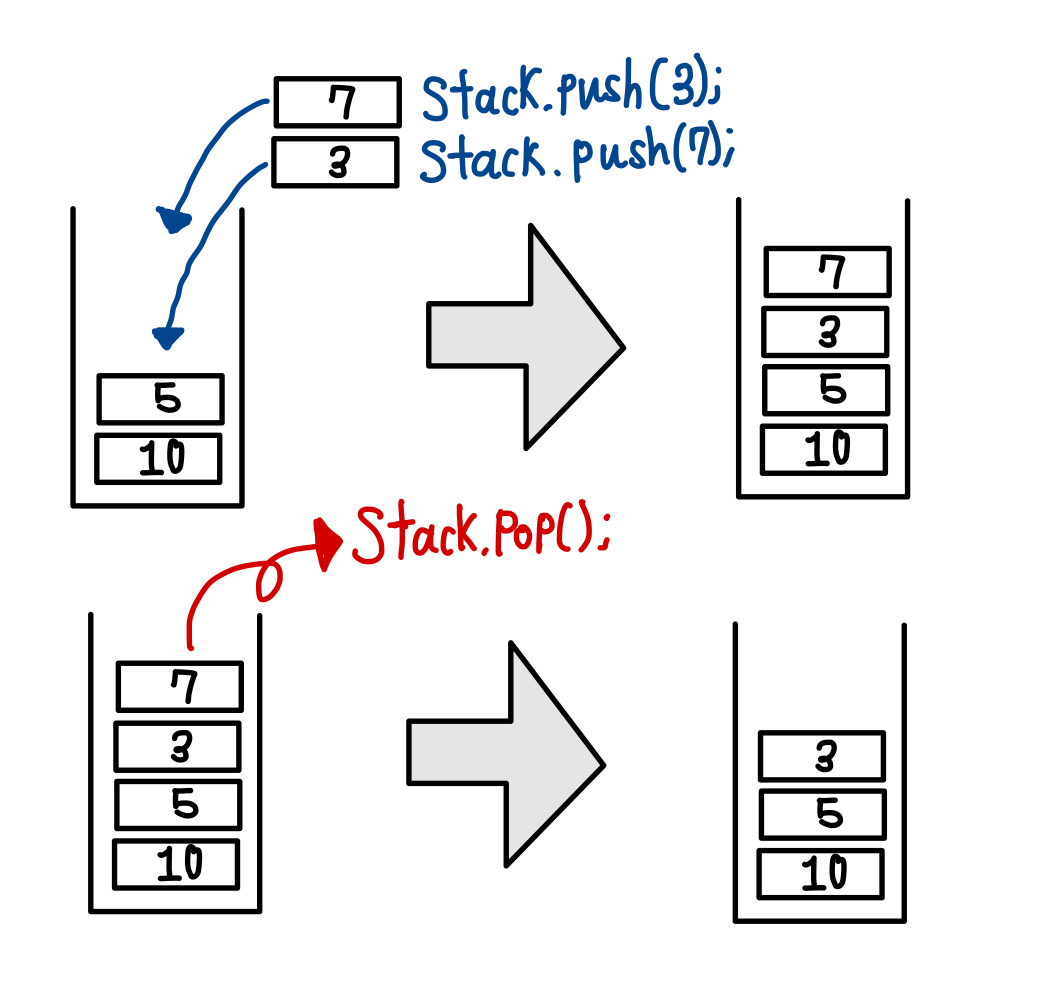
#include <iostream>
#include <stack>
using namespace std;
int main(void){
stack<int> stk; //스택 생성자
stack<int> STK;
stk.empty(); //비어있으면 true, 아니면 false 반환
stk.size(); //스택의 요소 개수 반환
stk.top(); //스택의 맨 위에 있는 원소 반환, 값 조작 가능
stk.push(1); //스택에 1 삽입
stk.emplace(2); //스택에 2 삽입
stk.pop(); //스택의 맨 위 원소 제거
stk.swap(STK); //상호 교환, 같은 타입끼리만 가능
return 0;
}
참고 문언 : https://cplusplus.com/reference/vector/vector/
vector - C++ Reference
difference_typea signed integral type, identical to: iterator_traits ::difference_type usually the same as ptrdiff_t
cplusplus.com
'C&C++' 카테고리의 다른 글
| const 개념 확실히 잡기 (0) | 2022.10.13 |
|---|